Announcing etcd 3.5
When we launched etcd 3.4 back in August 2019, our focus was on storage backend improvements, non-voting member and pre-vote features. Since then, etcd has become more widely used for various mission critical clustering and database applications and as a result, its feature set has grown more broad and complex. Thus, improving its stability and reliability has been top priority in recent development.
Today, we are releasing etcd 3.5. The past two years allowed for extensive iterations in fixing numerous bugs, identifying optimization opportunities at scale, and evolving its surrounding ecosystem. The etcd project also became a CNCF graduated project during this time frame. This release is the result of continuous evolution and grungy, thankless tasks done by the etcd community.
In this blog post, we review the most notable changes to etcd 3.5, and present a project road map for future releases. For a complete list of changes, see CHANGELOG 3.5. For more updates, follow us on Twitter @etcdio. To get etcd, see Install.
Security
Given that etcd often handles sensitive data, improving and maintaining security posture is our highest priority. In order to have a comprehensive understanding of etcd security landscape, we completed third-party security audits: The first report was published in February 2020, where we identified (and fixed) various edge cases and high severity issues. For more information, see security audit report.
To adhere to the highest levels of security best practices, etcd now has a
security release
process,
and runs automated tests with static analysis tools, such as errcheck,
ineffassign, and others.
Features
The migration to structured logging is complete. etcd now defaults to zap logger that has a reflection-free, zero-allocation JSON encoder. We have deprecated capnslog that logged with reflection-based serialization.
etcd now supports built-in log rotation that configures rotate thresholds, compression algorithms, etc. For more information, see hexfusion@ of Red Hat’s code change.
etcd now emits more detailed tracing information for expensive requests, such as:
{
"caller":"traceutil/trace.go:116",
"msg":"trace[123] range",
"detail":"{
range_begin:foo;
range_end:fooo; response_count:100000; response_revision:191496;}",
"duration":"132.449773ms",
"start":"...:32.611-0700",
"end":"...:32.744-0700",
"steps":[
"trace[123] step 'range keys from bolt db' (duration: 92.521911ms)",
"trace[123] step 'filter and sort the key-value pairs' (duration: 22.789099ms)"]}
This provides a very useful signal for understanding the lifetime of a request spanning multiple etcd server components. See YoyinZyc@’s code change (from Google).
Each etcd cluster maintains its own cluster version, a value agreed on by the quorum of the cluster. Previously, downgrading such cluster versions (e.g., etcd minor version from 3.5 to 3.4) was not supported in order to protect against incompatible changes.
Let’s say we allow 3.3 node to join 3.4 cluster and send a lease checkpoint request to the leader, which was introduced only in etcd 3.4. When 3.3 node receives the lease checkpoint request, it fails to handle the unknown apply request (see etcd server apply code). However, one might not use such a lease checkpointer feature and be willing to risk incompatible changes in order to perform emergency rollbacks (e.g., major defect in new etcd versions). To ensure such rollbacks are easy and reliable, we’ve added a downgrade API that validates, enables, and cancels etcd version downgrades. For more information, see YoyinZyc@ of Google’s code change .
By requiring quorum agreement, etcd cluster membership applies with the same level of consistency as writes. Previously however, the member list call was directly served from the server’s local data, which could be stale. Now, etcd serves the member list with a linearizable guarantee — if the server is disconnected from the quorum, the member list call will fail. See jingyih@ of Google’s code change.
gRPC gateway endpoint is now stable under /v3/*. gRPC gateway generates an
HTTP API to make etcd gRPC-based HTTP/2 protocol accessible via HTTP/1, such as:
curl -X POST -L http://localhost:2379/v3/kv/put -d '{"key": "Zm9v", "value": "YmFy"}'
etcd client now uses the latest gRPC, v1.32.0, requires a new
import path "go.etcd.io/etcd/client/v3", and migrates balancer
implementation upstream. For more information, see ptabor@ of
Google’s code change.
Bug fixes
etcd reliability and correctness are of utmost importance. That is why we backport all critical bug fixes to previous etcd releases. The following are the notable bugs we identified and fixed during etcd 3.5 development:
- Lease objects piling up caused memory leaks, and the solution was to clear the expired lease queue in the old leader. For details, see tangcong@ of Tencent’s fix.
- Ongoing compact operation caused deadlock in mvcc storage layer. For details, see tangcong@ of Tencent’s fix.
- etcd server restart had redundant backend database open operations and as a result, reloading 40-million keys took over 5-minutes, and the solution reduced the restart time by half. For details, see tangcong@ of Tencent’s fix.
- If etcd crashed before completing defragmentation, the next defragment operation might have read the corrupted file. The solution was to ignore and overwrite the existing file. See jpbetz@ of Google’s fix.
- Client cancelling watch did not signal the server to create leaky watchers. The solution was to explicitly send a cancel request to the server. See jackkleeman@ of Apple’s fix.
Performance
Kubernetes, the most prominent user of etcd, queries the entire keyspace to list
and watch its cluster resources. This range query happens whenever the resource
is not found in the kube-apiserver reflector cache (e.g., requested etcd revision
has been compacted, see kube-apiserver v1.21
code),
often causing slowness in reads from overloaded etcd servers (see GitHub
issue). In such cases,
kube-apiserver tracing warns as below:
"List" url:/api/v1/pods,user-agent... (started: ...) (total time: 1.208s): Trace[...]: [1.208s] [1.204s] Writing http response done count:4346
And etcd warns as follows:
etcdserver: read-only range request key:"/registry/pods/" range_end:"/registry/pods0" revision:... range_response_count:500 size:291984 took too long (723.099118ms) to execute
Our deep-dive into etcd heap profile uncovered major inefficiency in the server
warning logger that had a redundant encoding operation only to compute the size
of range responses with
proto.Size
call. As a result, a large range query had up to 60% heap allocation overhead,
thus causing out-of-memory crashes, or OOM, in overloaded etcd servers (see
Figure 1). We optimized the protocol buffer message size operation
and as a result, reduced etcd memory consumption up to 50% during peak usage (see
Figure 2). It was a set of small code changes, but for years, such performance
achievements were invisible without extensive testing and workload simulation. See
chaochn47@ of Amazon Web
Services’s investigation and patch to replace
proto.Size calls.

Figure 1: etcd heap usage during a slow request warn logging for computing response size of a protocol buffer message. 61% of the heap was allocated in the proto.Size call path that encodes all key-value pairs in the message to compute the size.

Figure 2: etcd heap usage during range query before and after replacing the proto.Size call. Optimizing the proto.Size call in the etcd server reduced memory usage up to 50%.
The etcd 3.4 release made backend read transactions fully concurrent by copying transaction buffers rather than sharing between writes and concurrent reads (see code change from 3.4 release). However, such a buffering mechanism comes with unavoidable copy overhead and negatively impacted write-heavy transaction performance, as creating concurrent read transactions acquires a mutex lock which then blocks incoming write transactions.
etcd 3.5 improvements further increase transaction concurrency.
If a transaction includes a
PUT(update) operation, the transaction instead shares the transaction buffer between reads and writes (same behavior as 3.3) in order to avoid copying buffers. This transaction mode can be disabled viaetcd --experimental-txn-mode-write-with-shared-buffer=false.The benchmark results show that the transaction throughput with a high write ratio has increased up to 2.7 times by avoiding copying buffers when creating a write transaction (see Figures 3 and 4). This benefits all kube-apiserver create and update calls that use etcd transactions (see etcd3 store v1.21 code). For more information, see wilsonwang371@ of ByteDance’s code change and benchmark results.
 Figure 3: etcd transaction ratio with a high write ratio. The value at the top is the ratio of reads and writes. The first ratio, 0.125, is 1 read per 8 writes. The second ratio, 0.25, is 1 read for 4 writes. The value at the right bar represents the inverse ratio of transaction throughput before and after etcd/pull/12896. With the shared buffer approach for writes, the transaction throughput is increased up to 2.7 times.
Figure 3: etcd transaction ratio with a high write ratio. The value at the top is the ratio of reads and writes. The first ratio, 0.125, is 1 read per 8 writes. The second ratio, 0.25, is 1 read for 4 writes. The value at the right bar represents the inverse ratio of transaction throughput before and after etcd/pull/12896. With the shared buffer approach for writes, the transaction throughput is increased up to 2.7 times.
Figure 4: etcd transaction ratio with a high read ratio. The value at the top is the ratio of reads and writes. The first ratio, 4.0, is 4 reads per 1 write. The second ratio, 8.0, is 8 reads per 1 write. The value at the right bar represents the inverse ratio of transaction throughput before and after etcd/pull/12896. With the shared buffer approach for writes, the transaction throughput is increased up to 25%.
etcd now caches the transaction buffer to avoid the unnecessary copy operations. This speeds up concurrent read transaction creation and as a result, the transaction with a high read ratio has increased up to 2.4 times (see Figures 5 and 6). See wilsonwang371@ of ByteDance’s code change and benchmark results.

Figure 5: etcd transaction ratio with a high write ratio. The value at the top is the ratio of reads and writes. The first ratio, 0.125, is 1 read per 8 writes. The second ratio, 0.25, is 1 read per 4 writes. The value at the right bar represents the inverse ratio of transaction throughput before and after etcd/pull/12933. With the caching mechanism for read transactions, the transaction throughput is increased up to 1.4 times.

Figure 6: etcd transaction ratio with a high read ratio. The value at the top is the ratio of reads and writes. The first ratio, 4.0, is 4 reads per 1 write. The second ratio, 8.0, is 8 reads per 1 write. The value at the right bar represents the inverse ratio of transaction throughput before and after etcd/pull/12933. With the caching mechanism for read transactions, the transaction throughput is increased up to 2.5 times.
Monitoring
Long-running load tests revealed that etcd server misrepresented its real memory
usage by masking the impact of Go garbage collection. We discovered that etcd server with Go 1.12 changed the runtime to use MADV_FREE in Linux kernel, and as a result, reclaimed memory was not
reflected in the resident set size, or RSS, metric. This had made the etcd memory
usage metric inaccurately static, thus showing no sign of Go garbage collection.
To fix this monitoring problem, we compile etcd 3.5 with Go 1.16 that defaults
to MADV_DONTNEED on Linux. For more information, see Figure 7 and GitHub Go issue 42330.
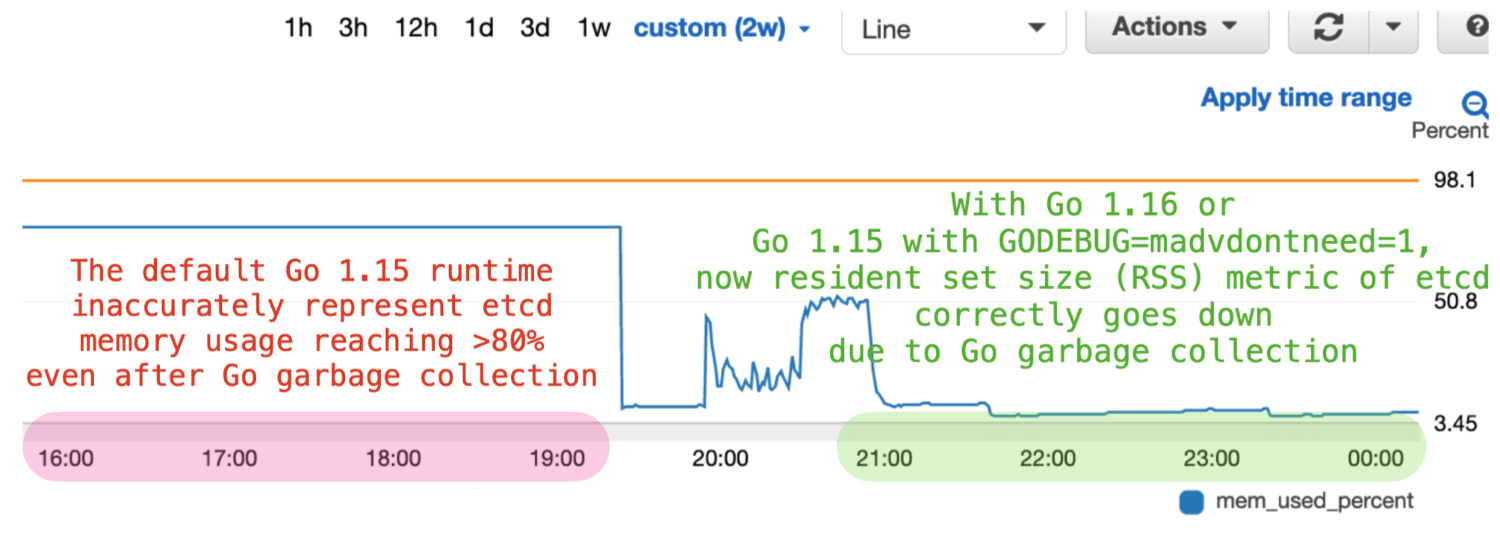
Figure 7: etcd memory usage during range query before and after setting MADV_DONTNEED in Go runtime. When run with GODEBUG=madvdontneed=1" or Go v1.16 or later, the etcd server accurately reports its memory usage in the CloudWatch mem_used metric or other monitoring tools such as top.
Monitoring is a fundamental service for reliability and observability. Monitoring enables individual service owners to understand the current state and identify possible causes for problem reports. Known as telemetry, the goal is to detect early warning signs and diagnose potential issues. etcd creates server logs with tracing information and publishes Prometheus metrics.
This information helps us determine possible
service impacts and causes. However, when a request call chain spans
multiple external components (e.g., from kube-apiserver to etcd), it is harder
to identify the issue. In order to efficiently identify the root cause, we
added distributed tracing support using
OpenTelemetry: When the distributed tracing is
enabled, etcd now uses OpenTelemetry to produce a trace across the RPC call
chain and thus easily integrate with the surrounding ecosystem. See
Figure 8, lilic@ of Red Hat’s proposal, and GitHub issue 12460.
Figure 8: Example jaeger tracing UI for etcd.
Testing
Distributed systems are full of subtle edge cases. The fact that a bug may only emerge under special circumstances warrants exhaustive test coverage beyond simple unit testing. etcd runs integration, end-to-end, and failure injection tests, which provide a reliable and faster way to validate each change. However, as development continued with extended feature sets, flaky tests quickly piled up draining our productivity. So, we took on the series of arduous tasks that often required multiple hours of debugging to root cause of failures to improve test quality. Some notable changes include the following:
- reduce unit tests runtime by half
- configure test logger
- simplify test data cleanup
- close gRPC servers after tests
Platforms
etcd presubmit tests are now fast and reliable, but were mostly running on x86 processors. And there have been numerous requests to support other architectures like ARM (see GitHub issue 12852) and s390x (see GitHub issue 11163). A self-hosted GitHub action runner provides a consistent way of hosting various external test workers (see GitHub issue 12856). Using the GitHub action, etcd now runs tests on ARM-based AWS EC2 instances (Graviton), thereby officially supporting ARM64 (aarch64) platform. In addition, we introduced a mechanism to support other platforms and categorized support tiers based on testing coverage. For more information, see the Supported platforms documentation PR 273 and the Supported platforms documentation.
Developer experience
To better support integration with external projects, etcd now fully adopts the Go 1.16 module. This brought challenges as the existing codebase made migration arduous, causing concerns regarding adoption in the community). Tooling is an important part of etcd development and as a result, we needed a better solution to support our contributor experience.
Using Go module enables clear
separation between server and client code, ease of change management for
dependency updates, and verifiable build system without a convoluted codebase for
vendoring. With reproducible builds in place, we eliminated the need for
vending dependency and as a result, we reduced the etcd codebase size by half.
See ptabor@ of Google’s modularization proposal
and code change to remove the vendor
directory.
To better isolate dependency trees, the etcd command-line interface now has a new
administrative tool etcdutl (not etcdut-i-l), and the sub-commands
include etcdutl snapshot and etcdutl defrag: The etcdctl snapshot and etcdctl defrag commands in previous releases are deprecated.
This change aligns well with the new Go module layouts: etcdctl solely relies
on client v3 libraries, whereas etcdutl might depend on etcd server-side
packages, such as bolt and backend database code. See ptabor@ of Google’s code change.
To support inclusive naming initiatives, etcd
projects renamed the default branch master to main (see etcd-io/etcd
change and etcd-io/website
change). The migration was
seamless as GitHub handles the necessary redirects (see GitHub
renaming).
Each etcd write incurs an append message in Raft thus fsynced to disk. However, such
persistence might not be desirable for testing. To work around this, we’ve added the
etcd --unsafe-no-fsync flag to bypass disk writes for Raft WAL entries. See
crawshaw@ of Tailscale’s code change and GitHub
issue 11930.
Community
The diversity of etcd end users keeps expanding: Cloudflare relies on etcd for managing its data center, Grafana Cortex stores its configuration data in etcd, Netflix Titus uses etcd for managing its container workloads, and Tailscale runs its control plane on top of etcd.
We have also extended our team of vendor contributors. In the etcd 3.5 release, we’ve added two core maintainers; Wenjia Zhang of Google, who’s been leading etcd community meetings and Kubernetes integration, and Piotr Tabor of Google, who’s been leading numerous bug fixes and codebase modularization work.
The diversity of contributors is key to building a sustainable, welcoming open source project and fostering manageable work environments.
See the 2021 CNCF etcd project journey report for more information.
New etcd.io
Since etcd joined Cloud Native Computing Foundation (CNCF) in December 2018, we have refactored all user-facing documentation into a dedicated repository etcd-io/website and modernized its website hosting with Hugo). The migration was a huge undertaking that required multiple months of engineering efforts and communication between maintainers. The very blog post you are reading now is hosted on the new etcd.io, thanks to lucperkins@, chalin@ of CNCF, nate-double-u@ of CNCF, and many other community contributors.
Future roadmaps
Traffic overloads can cause cascading node failures and as a result, scaling such clusters becomes challenging and could impair the ability to recover from quorum loss. With so many mission critical systems built on top of etcd, defending etcd against overload is paramount. We will revisit the etcd throttle feature to shed excessive loads gracefully. Currently, the etcd project has two pending rate-limiter proposals: vivekpatani@ of Apple’s proposal and tangcong@ of Tencent’s proposal.
Large range querying from kube-apiserver is still the most challenging source of
process crashing, as it is relatively unpredictable. Our heap profile on such
workloads found that the etcd range request handler decodes and holds the entire
response before sending it out to gRPC server, adding up to 37% heap
allocation. See Figure 9 and chaochn47@ of Amazon Web
Services’s investigation.
Paginating range calls in client code doesn’t fully address the issue, because it entails additional consistency considerations and still requires full relists for expired resources. For more information, see kube-apiserver v1.21 code). To work around this inefficiency, etcd needs to support range streams. We will revisit yangxuanjia@ of JD’s range stream proposal, as it requires a significant level of effort to introduce such semantic changes in etcd and in downstream projects.

Figure 9: etcd usage during a range query for listing Kubernetes pods. 37% of the heap was allocated in etcd mvcc rangeKeys to hold key-value pairs for creating a range query response.
In order to reduce maintenance overhead, we are completely deprecating
the etcd v2 API in favor of a more performant and widely adopted v3 API.
The v2 storage translation layer via etcd --experimental-enable-v2v3
remains experimental in 3.5 and to be removed in the
next release. For details, see
ptabor@ of Google’s proposal.
Historically, etcd releases have been a large undertaking due to infrequency, because of the large delta, and a need for release automation. We will develop an automated release system that is more accessible to the community.