etcd learner design
etcd Learner
Gyuho Lee (github.com/gyuho, Amazon Web Services, Inc.), Joe Betz (github.com/jpbetz, Google Inc.)
Background
Membership reconfiguration has been one of the biggest operational challenges. Let’s review common challenges.
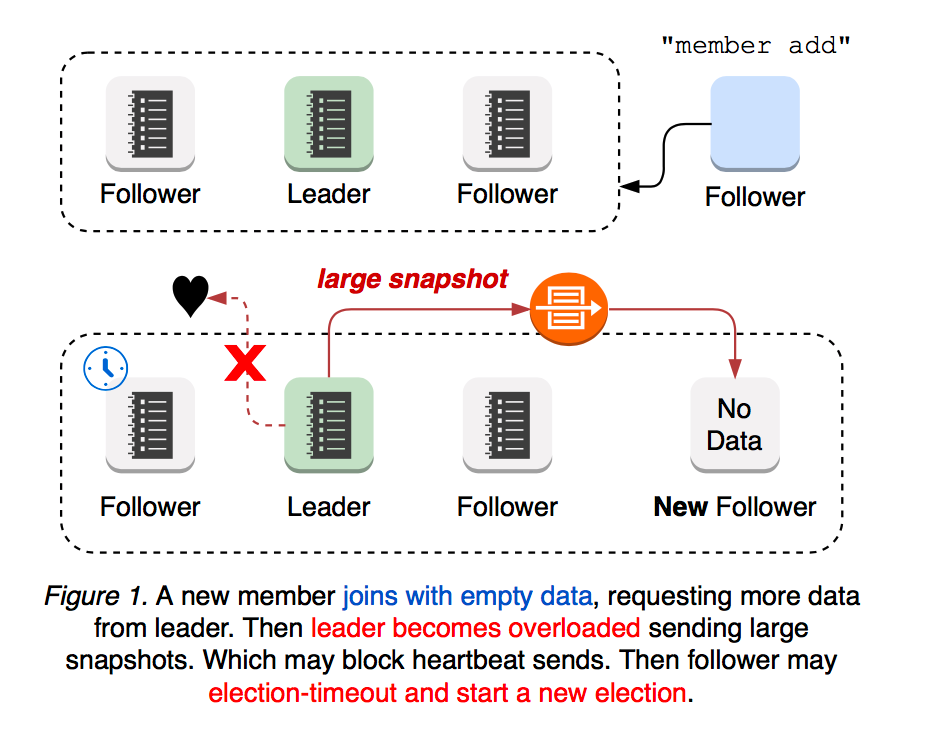
1. New Cluster member overloads Leader
A newly joined etcd member starts with no data, thus demanding more updates from leader until it catches up with leader’s logs. Then leader’s network is more likely to be overloaded, blocking or dropping leader heartbeats to followers. In such case, a follower may election-timeout to start a new leader election. That is, a cluster with a new member is more vulnerable to leader election. Both leader election and the subsequent update propagation to the new member are prone to causing periods of cluster unavailability (see Figure 1).
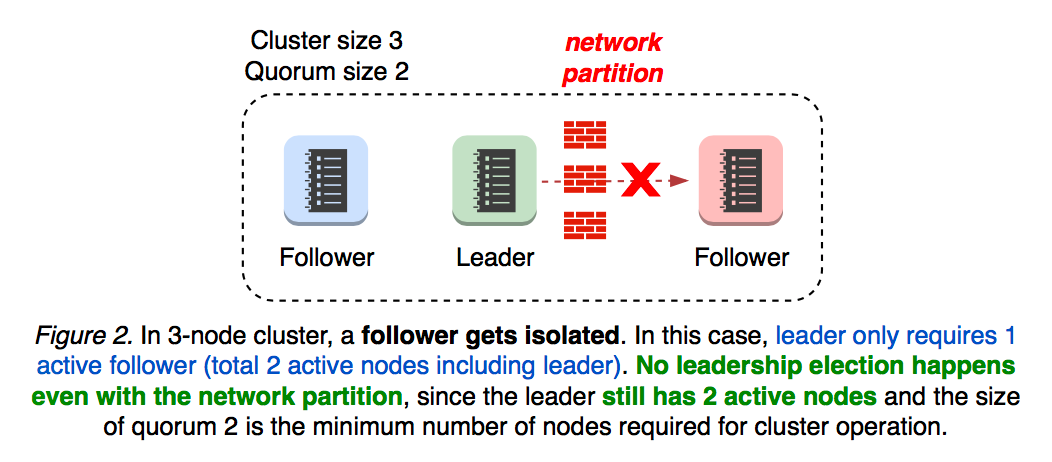
2. Network Partitions scenarios
What if network partition happens? It depends on leader partition. If the leader still maintains the active quorum, the cluster would continue to operate (see Figure 2).
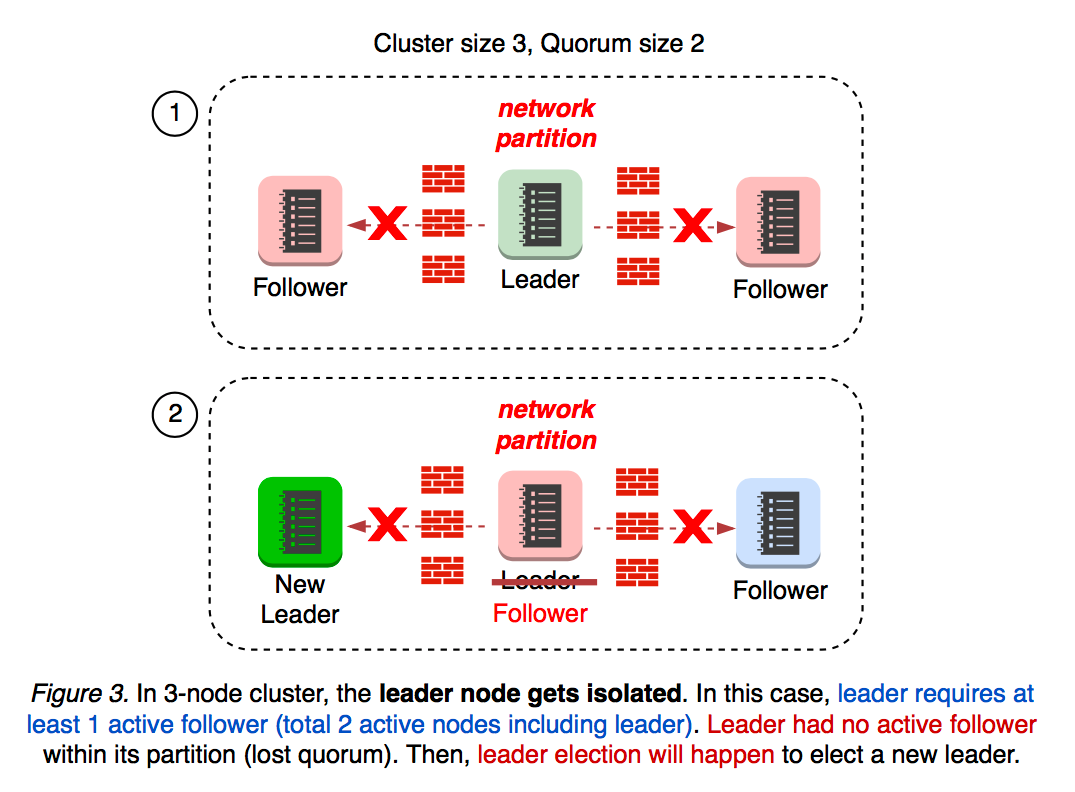
2.1 Leader isolation
What if the leader becomes isolated from the rest of the cluster? Leader monitors progress of each follower. When leader loses connectivity from the quorum, it reverts back to follower which will affect the cluster availability (see Figure 3).
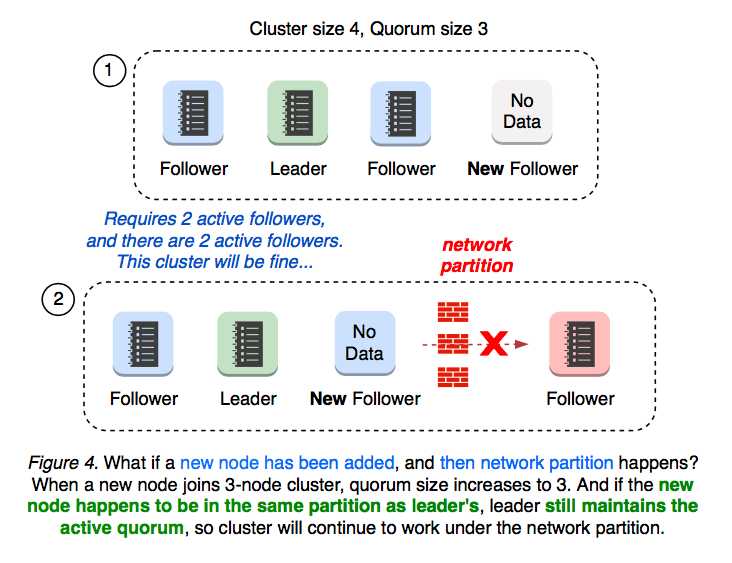
When a new node is added to 3 node cluster, the cluster size becomes 4 and the quorum size becomes 3. What if a new node had joined the cluster, and then network partition happens? It depends on which partition the new member gets located after partition.
2.2 Cluster Split 3+1
If the new node happens to be located in the same partition as leader’s, the leader still maintains the active quorum of 3. No leadership election happens, and no cluster availability gets affected (see Figure 4).
2.3 Cluster Split 2+2
If the cluster is 2-and-2 partitioned, then neither of partition maintains the quorum of 3. In this case, leadership election happens (see Figure 5).
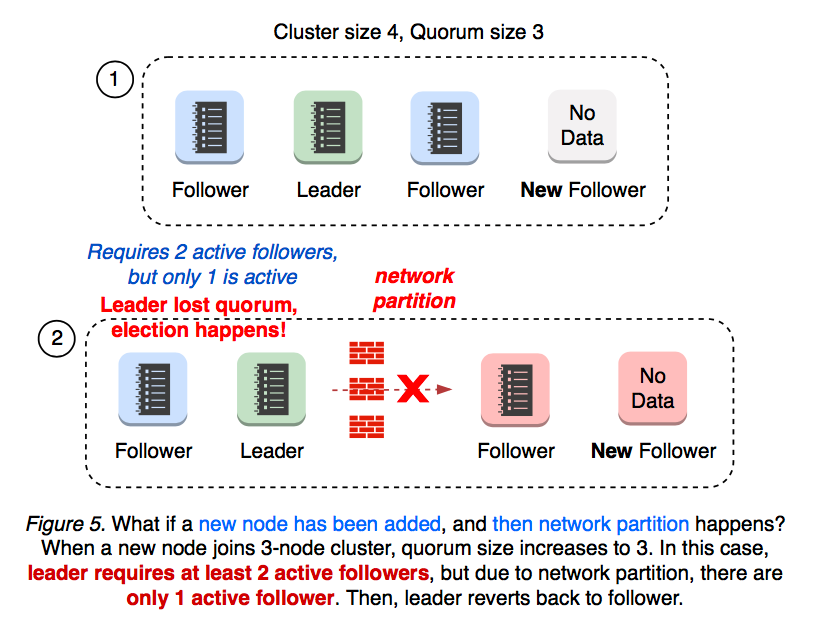
2.4 Quorum Lost
What if network partition happens first, and then a new member gets added? A partitioned 3-node cluster already has one disconnected follower. When a new member is added, the quorum changes from 2 to 3. Now, this cluster has only 2 active nodes out 4, thus losing quorum and starting a new leadership election (see Figure 6).
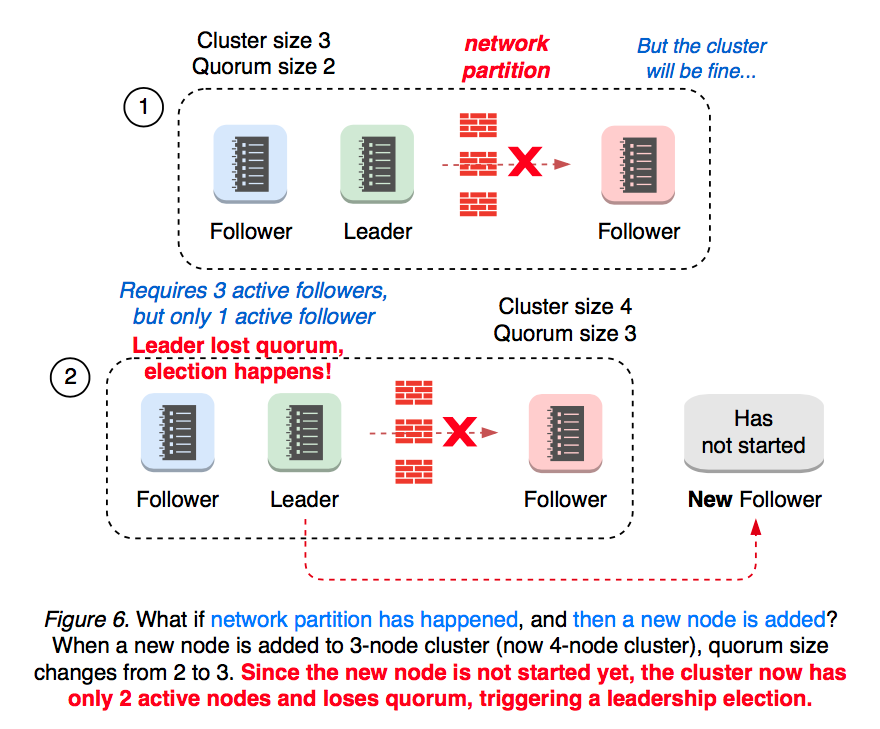
Since member add operation can change the size of quorum, it is always recommended to “member remove” first to replace an unhealthy node.
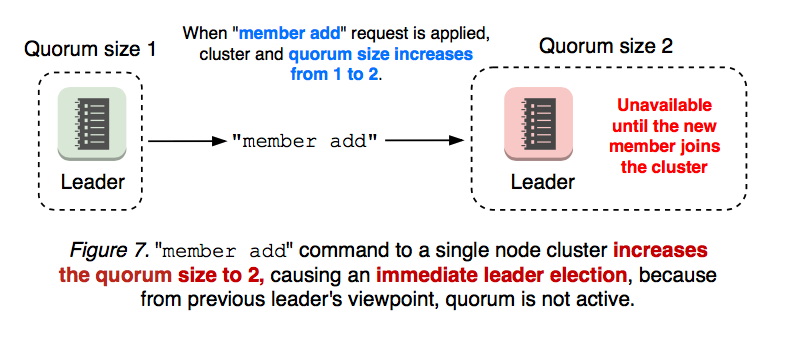
Adding a new member to a 1-node cluster changes the quorum size to 2, immediately causing a leader election when the previous leader finds out quorum is not active. This is because “member add” operation is a 2-step process where user needs to apply “member add” command first, and then starts the new node process (see Figure 7).
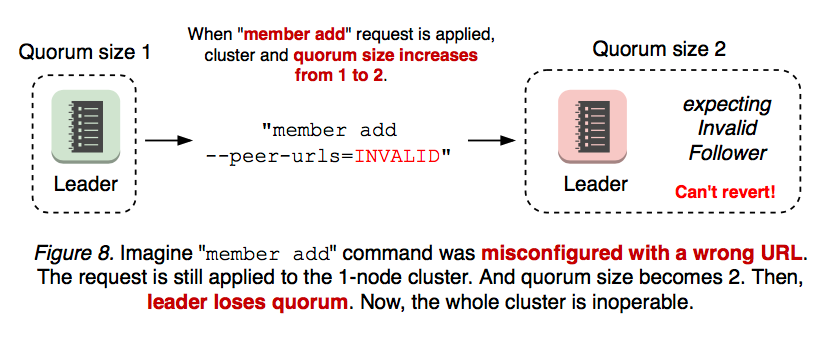
3. Cluster Misconfigurations
An even worse case is when an added member is misconfigured. Membership reconfiguration is a two-step process: “etcdctl member add” and starting an etcd server process with the given peer URL. That is, “member add” command is applied regardless of URL, even when the URL value is invalid. If the first step is applied with invalid URLs, the second step cannot even start the new etcd. Once the cluster loses quorum, there is no way to revert the membership change (see Figure 8).
Same applies to a multi-node cluster. For example, the cluster has two members down (one is failed, the other is misconfigured) and two members up, but now it requires at least 3 votes to change the cluster membership (see Figure 9).
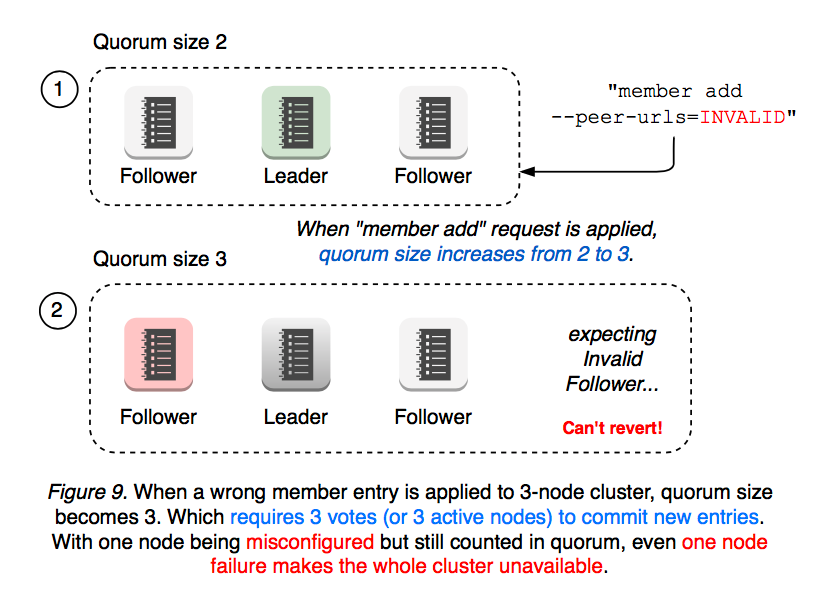
As seen above, a simple misconfiguration can fail the whole cluster into an inoperative state. In such case, an operator need manually recreate the cluster with etcd --force-new-cluster flag. As etcd has become a mission-critical service for Kubernetes, even the slightest outage may have significant impact on users. What can we better to make etcd such operations easier? Among other things, leader election is most critical to cluster availability: Can we make membership reconfiguration less disruptive by not changing the size of quorum? Can a new node be idle, only requesting the minimum updates from leader, until it catches up? Can membership misconfiguration be always reversible and handled in a more secure way (wrong member add command run should never fail the cluster)? Should an user worry about network topology when adding a new member? Can member add API work regardless of the location of nodes and ongoing network partitions?
Raft Learner
In order to mitigate such availability gaps in the previous section, Raft §4.2.1 introduces a new node state “Learner”, which joins the cluster as a non-voting member until it catches up to leader’s logs.
Features in v3.4
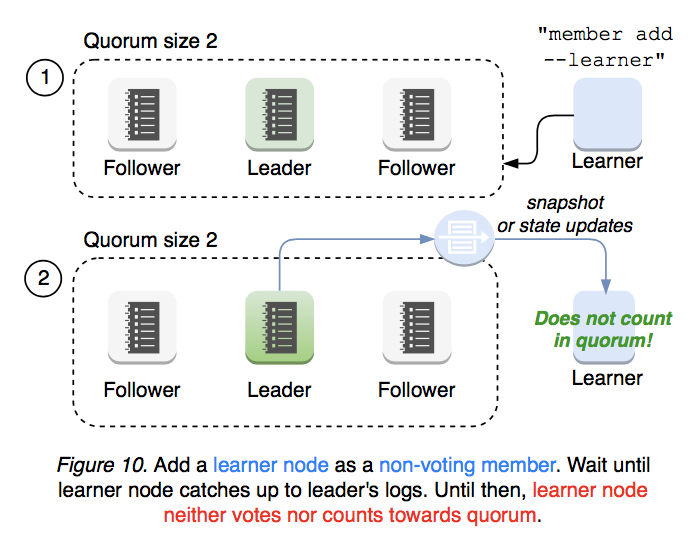
An operator should do the minimum amount of work possible to add a new learner node. member add --learner command to add a new learner, which joins cluster as a non-voting member but still receives all data from leader (see Figure 10).
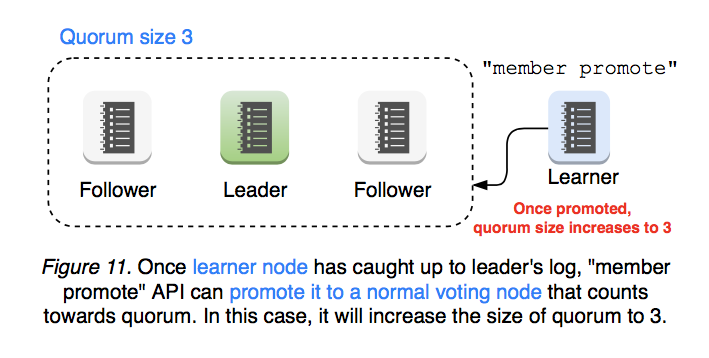
When a learner has caught up with leader’s progress, the learner can be promoted to a voting member using member promote API, which then counts towards the quorum (see Figure 11).
etcd server validates promote request to ensure its operational safety. Only after its log has caught up to leader’s can learner be promoted to a voting member (see Figure 12).

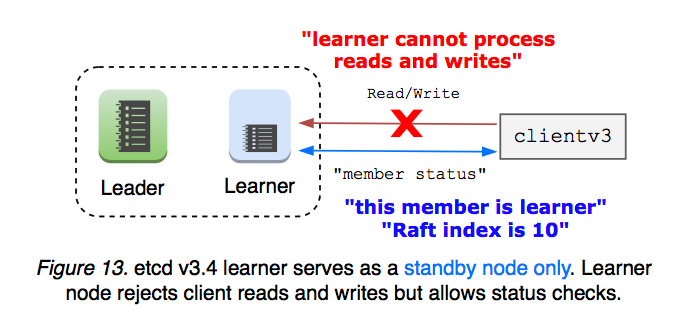
Learner only serves as a standby node until promoted: Leadership cannot be transferred to learner. Learner rejects client reads and writes (client balancer should not route requests to learner). Which means learner does not need issue Read Index requests to leader. Such limitation simplifies the initial learner implementation in v3.4 release (see Figure 13).
In addition, etcd limits the total number of learners that a cluster can have, and avoids overloading the leader with log replication. Learner never promotes itself. While etcd provides learner status information and safety checks, cluster operator must make the final decision whether to promote learner or not.
Proposed features for future releases
Make learner state only and default: Defaulting a new member state to learner will greatly improve membership reconfiguration safety, because learner does not change the size of quorum. Misconfiguration will always be reversible without losing the quorum.
Make voting-member promotion fully automatic: Once a learner catches up to leader’s logs, a cluster can automatically promote the learner. etcd requires certain thresholds to be defined by the user, and once the requirements are satisfied, learner promotes itself to a voting member. From a user’s perspective, “member add” command would work the same way as today but with greater safety provided by learner feature.
Make learner standby failover node: A learner joins as a standby node, and gets automatically promoted when the cluster availability is affected.
Make learner read-only: A learner can serve as a read-only node that never gets promoted. In a weak consistency mode, learner only receives data from leader and never process writes. Serving reads locally without consensus overhead would greatly decrease the workloads to leader but may serve stale data. In a strong consistency mode, learner requests read index from leader to serve latest data, but still rejects writes.
Learner vs. Mirror Maker
etcd implements “mirror maker” using watch API to continuously relay key creates and updates to a separate cluster. Mirroring usually has low latency overhead once it completes initial synchronization. Learner and mirroring overlap in that both can be used to replicate existing data for read-only. However, mirroring does not guarantee linearizability. During network disconnects, previous key-values might have been discarded, and clients are expected to verify watch responses for correct ordering. Thus, there is no ordering guarantee in mirror. Use mirror for minimum latency (e.g. cross data center) at the costs of consistency. Use learner to retain all historical data and its ordering.
Appendix: Learner Implementation in v3.4
Expose “Learner” node type to “MemberAdd” API.
etcd client adds a flag to “MemberAdd” API for learner node. And etcd server handler applies membership change entry with pb.ConfChangeAddLearnerNode type. Once the command has been applied, a server joins the cluster with etcd --initial-cluster-state=existing flag. This learner node can neither vote nor count as quorum.
etcd server must not transfer leadership to learner, since it may still lag behind and does not count as quorum. etcd server limits the number of learners that cluster can have to one: the more learners we have, the more data the leader has to propagate. Clients may talk to learner node, but learner rejects all requests other than serializable read and member status API. This is for simplicity of initial implementation. In the future, learner can be extended as a read-only server that continuously mirrors cluster data. Client balancer must provide helper function to exclude learner node endpoint. Otherwise, request sent to learner may fail. Client sync member call should factor into learner node type. So should client endpoints update call.
MemberList and MemberStatus responses should indicate which node is learner.
Add “MemberPromote” API.
Internally in Raft, second MemberAdd call to learner node promotes it to a voting member. Leader maintains the progress of each follower and learner. If learner has not completed its snapshot message, reject promote request. Only accept promote request if and only if: The learner node is in a healthy state. The learner is in sync with leader or the delta is within the threshold (e.g. the number of entries to replicate to learner is less than 1/10 of snapshot count, which means it is less likely that even after promotion leader would not need send snapshot to the learner). All these logic are hard-coded in etcdserver package and not configurable.
Reference
- Original github issue: etcd#9161
- Use case: etcd#3715
- Use case: etcd#8888
- Use case: etcd#10114
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.